Dev Tools
从0到1:大模型量化
在理解量化之前,必须先明确大语言模型(LLM)推理过程中的两个物理瓶颈:显存容量(VRAM Capacity)与显存带宽(Memory Bandwidth Bound)。
1. 核心痛点:为什么我们必须量化?
大模型的量化技术并非一蹴而就,而是一场在显存容量与带宽壁垒面前的工程进化史。本章将从历史演进、物理限制及核心优化手段三个维度剖析量化的必要性。
1.1 量化技术的演进脉络
量化技术并非一蹴而就,而是在硬件资源限制与模型规模爆炸的矛盾中,经历的一场从理论研究到工程普惠的范式迁移:
- 阶段一:早期理论奠基 (2015-2020) —— 从计算机视觉领域的“深度压缩”起步
- 核心内容:早在 LLM 出现前,以 MIT 韩松教授为代表的研究者通过《Deep Compression》等工作,提出了剪枝、量化与编码的组合框架。
- 局限性:该阶段多采用量化感知训练(QAT),对动辄数千亿参数、训练成本极高的 LLM 而言,其工程可行性较低。
- 阶段二:8-bit PTQ 的突破 (2022) —— 关键“异常值”的处理机制
- 技术里程碑:Tim Dettmers 团队提出的 LLM.int8() 算法。
- 工程意义:研究者发现激活值中存在极少数(<0.1%)但影响全局的**“异常值(Outliers)”**。通过对这些权重保留 FP16 精度、其余使用 INT8 计算,首次实现了大模型在推理侧的“无损”训练后量化(PTQ)。
- 阶段三:4-bit 范式的确立 (2022末-2023中) —— 精度与效率的平衡点
- 核心驱动:GPTQ(基于数学补偿)与 AWQ(基于激活感知权重保护)的出现,确立了 4-bit 作为大模型部署的“最佳平衡位”。
- 微调革新:QLoRA 的诞生引入了 NF4 数据类型,降低了在消费级显卡上对大模型进行指令微调的门槛。
- 阶段四:生态标准化与工程下沉 (2023初-至今) —— 格式大一统与跨平台普及
- 核心推动:llama.cpp 项目及其配套的 GGUF 格式。
- 成果:通过极致的 C++ 工程优化,量化模型脱离了对复杂 Python 栈和顶级 CUDA 框架的依赖,实现了在 Windows、Mac 甚至移动终端上的快速部署。
尾声与未来:迈向 1-bit 时代 量化的故事到 4-bit 并没有结束。如今的 AI 巨头们正在研究极其疯狂的 1.58-bit 量化(如微软的 BitNet b1.58)。 在这种模型里,所有的权重只有三个状态:-1、0、1。 这意味着,大模型推理时将彻底消灭极其耗电的“浮点乘法”运算,全部变成最简单的“整数加减法”。如果这个技术在未来一两年内成熟并开源,你家里的显卡性能(在 AI 推理上)可能会瞬间暴涨 10 倍以上。
2. 量化的数学本质
量化(Quantization)是一种有损压缩技术,其核心思想是将高精度的浮点数(如 BF16)映射到低精度的离散整数(如 INT8, INT4 甚至 INT2)上。最基础的线性量化(Linear Quantization)公式可以表示为:
$q = \text{round}\left( \frac{f}{S} \right) + Z$
其中:
- $f$ 是原始的浮点数权重。
- $S$ 是缩放因子(Scale Factor),用于将浮点数的动态范围映射到整数的范围内。
- $Z$ 是零点偏移(Zero Point),用于处理非对称分布。
- $q$ 是量化后的低位宽整数。
在反量化(Dequantization,即推理时将整数还原为浮点数交给计算单元)时:
$f’ = S \times (q - Z)$
显然,$f’$ 并不完全等于最初的 $f$,两者之间的差值就是量化误差(Quantization Error)。量化算法的核心,就是在给定的位宽下,极力缩小这个误差。
3. GGUF 与 K-Quants:核心基石
在搜索 Qwen 3.5 时,你可能会看到大量带有后缀的模型文件(如 Qwen-3.5-7B-Instruct-Q4_K_M.gguf)。这套体系基于 llama.cpp 项目创立的 GGUF 格式。
为了解决早期粗暴的全局量化导致的“智商大幅衰减”问题,社区引入了分组量化(Block-wise Quantization)和混合精度量化(K-Quants)。
3.1 分组量化 (Block/Group)
不再为整个网络计算单一的缩放因子 $S$,而是将权重切分成大小为 32 或 256 的块(Block),每个块单独计算和存储自己的 $S$ 和 $Z$。这极大地保留了局部权重的数值分布特征。
3.2 K-Quants 混合精度策略
神经网络中不同层的参数对最终输出结果的“敏感度”是不同的。比如,注意力机制(Attention)中的某些投影层至关重要,而某些前馈神经网络(FFN)层的冗余度很高。K-Quants 算法会根据层的敏感度分配不同的量化位宽。
Q4_K_M(Medium):目前公认的甜点级。对重要的张量(Tensors)使用6-bit(Q6_K),对非重要张量使用4-bit。它在体积只比纯 4-bit 略大的情况下,保留了近乎 Q5 的精度。Q4_K_S(Small):更为激进。所有张量基本都压进 4-bit,甚至部分使用 3-bit。体积最小,适合显存极度紧张的场景。Q8_0:基础的 8-bit 分组量化。体积是原版的一半,精度几乎是 100% 无损。
4. 硬核指南:如何精确计算显存需求?
为了确保模型不爆显存(OOM),你需要计算两部分总和:静态模型权重显存 + 动态上下文交互显存(余量)。
4.1 静态模型权重估算公式
由于混合精度量化(K-Quants)对不同网络层使用了不同的 bit 位宽,我们不能简单地用 4-bit = 0.5 Bytes 来算。
估算公式: $VRAM_{静态} \approx 模型参数量 \text{ (B)} \times 每参数平均占用 \text{ (Bytes)}$
常用量化格式乘数对照表:
- BF16 / FP16 (原版): $\times 2.00$ Bytes
- Q8_0: $\times 1.05$ Bytes(约压缩 47%)
- Q6_K: $\times 0.82$ Bytes(约压缩 59%)
- Q5_K_M: $\times 0.68$ Bytes(约压缩 66%)
- Q4_K_M: $\times \mathbf{0.60}$ Bytes(虽然叫 4-bit,但实际平均约 4.8-bit,最推荐)
- IQ3_M: $\times 0.45$ Bytes(极致压缩,参数量极大时才用)
计算演示:一个 32B 的模型,如果选用 Q4_K_M 量化: $VRAM_{静态} \approx 32 \times 0.60 = 19.2 \text{ GB}$
4.2 动态上下文 (KV Cache) 应该留多少余量?
为方便计算,建议遵循以下预留经验法则(Rule of Thumb):
- 框架基础开销:CUDA 运行库本身需要占据约 0.5GB - 1GB。
- 轻度日常对话(2K - 4K Tokens):建议预留 1GB - 2GB。
- 中度阅读与长代码(8K - 16K Tokens):建议预留 3GB - 5GB。
- 超长文本处理(32K+ Tokens):建议预留 8GB 以上。
5. 如何科学验证量化模型的“智商”与性能?
“Talk is cheap, show me the data.” 我们宣称 Q8 比 Q4 聪明(精度高),而 Q4 比 Q8 快(性能好),在 AI 行业内,这是通过以下四大维度的标准测试来严谨验证的:
5.1 底层理论指标 —— 困惑度 (Perplexity, PPL)
PPL 衡量的是模型在看到前半句话时,猜中下一个词的“犹豫程度”。模型越聪明,猜得越准,犹豫越少,PPL 值就越低。这是学术界衡量语言模型本身质量的最绝对金标准。
- 验证方法:在
llama.cpp中内置了perplexity工具。你向模型输入同一份维基百科的测试文本,分别用原版、Q8 和 Q4 跑一遍。 - 行业通用结论:以 7B 模型为例,BF16 原版与 Q8 的 PPL 差距仅在万分位;而 Q4 的 PPL 仅出现极其轻微的退化(在可接受范围内)。
5.2 静态考卷刷题 —— 自动化基准测试 (Benchmarks)
PPL 是底层指标,而在实际应用中,我们需要看模型做具体任务的能力。行业内通常使用 lm-evaluation-harness(由 EleutherAI 开发)这样的自动化工具,让模型去做大量的标准化考卷。
针对程序员,最看重的是 HumanEval(代码生成)和 MMLU(多学科常识)。当你让模型分别以 BF16、Q8 和 Q4 去做 HumanEval 时,数据往往证明:Q4 相比原版,通过率只下降了微小的绝对百分比。
5.3 性能绝对指标 —— 吞吐量 (Throughput, Tokens/s)
为了验证“越小越快”的定律,我们不看智商,只看速度。
- 指标定义:生成阶段每秒能吐出多少个单词(Tokens per second)。
- 验证现象:在同一张显卡(如 RTX 4090)上跑同一个 32B 模型。跑 Q8_0 时生成速度可能是 15 tokens/s;跑 Q4_K_M 时,速度会飙升到约 28 tokens/s。这证明了大模型推理的瓶颈在于显存带宽,而非算力。
5.4 学术界铁证 —— “1%-2%”定律与量化悬崖 (Quantization Cliff)
为什么我们敢说从 8-bit 降到 4-bit,智商损失只有大约 1%-2%?这并非凭空捏造,而是基于顶级量化算法论文(GPTQ 与 AWQ)的实测数据:
- 平缓下坡 (8-bit 到 4-bit):在论文的标准数据集测试中,4-bit 权重量化相比 FP16 原版,得分平均只下降 1 到 2 个百分点。4-bit 因此被学术界公认为性价比最高的“最佳甜点位”。
- 断崖下跌 (低于 4-bit):一旦越过 4-bit 红线,尝试降到 3-bit (Q3) 或 2-bit (Q2),模型的准确率会突然出现 10%、20% 甚至 50% 的暴跌,出现严重的逻辑崩溃和幻觉。这在业界被称为**“量化悬崖(Quantization Cliff)”**。
⚠️ 规模前提:该定律仅适用于 7B 及以上的大模型。模型参数越大,内部“知识冗余度”越高,对量化的容忍度才越强。
参考文档
- Emergent Abilities of Large Language Models (Jason Wei et al., 2022)
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (Jason Wei et al., 2022)
- The case for 4-bit precision: k-bit Inference Scaling Laws (Tim Dettmers et al., 2022)
- GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers (2022)
- AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration (2023)
llama.cppOfficial GitHub Repositorylm-evaluation-harnessOfficial GitHub Repository- EleutherAI: Transformer Math 101
- Hugging Face Optimum Quantization Guide
ImageTagger for ImageGlass: 一款高效的图片标记工具
ImageTagger

![]()
![]()
1. 项目简介
ImageTagger 是一款基于 Windows Forms 的开源图像打标工具,专门为配合 ImageGlass 图片查看器使用而设计。
它允许用户在浏览图片的同时,通过简单的点击将图片分类到预定义的标签组中。借助于 ImageGlass Tools SDK,ImageTagger 实现了与查看器的实时路径同步和导航控制,极大地提升了海量图片的整理效率。
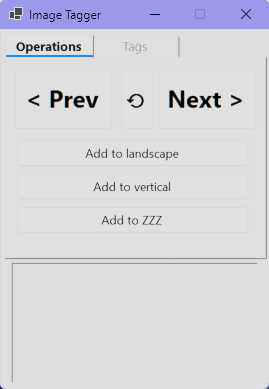
2. 核心特性
- 深度集成:与 ImageGlass 实时同步,支持自动跳转下一张。
- 灵活打标:一键添加、删除自定义标签,支持批量操作。
- 数据透明:使用简单的 JSON 格式存储打标数据。
- 置顶显示:默认窗口置顶,方便在全屏模式下无缝使用。
- 撤销支持:支持对误操作进行撤销。
3. 安装指南
3.1 前提条件
- Windows 操作系统。
- 已安装 .NET 8.0 Runtime。
- 已安装 ImageGlass。
3.2 安装步骤
- 前往
Releases下载最新压缩包。 - 将压缩包解压到本地固定目录。
- 集成到 ImageGlass:
- 打开 ImageGlass
Settings(设置)菜单。 - 导航至
Tools(工具)选项卡。 - 点击
Add...(添加)按钮并选择解压后的ImageTagger.exe。 - 在名称栏输入
ImageTagger即可。
- 打开 ImageGlass
4. 使用说明
4.1 启动与连接
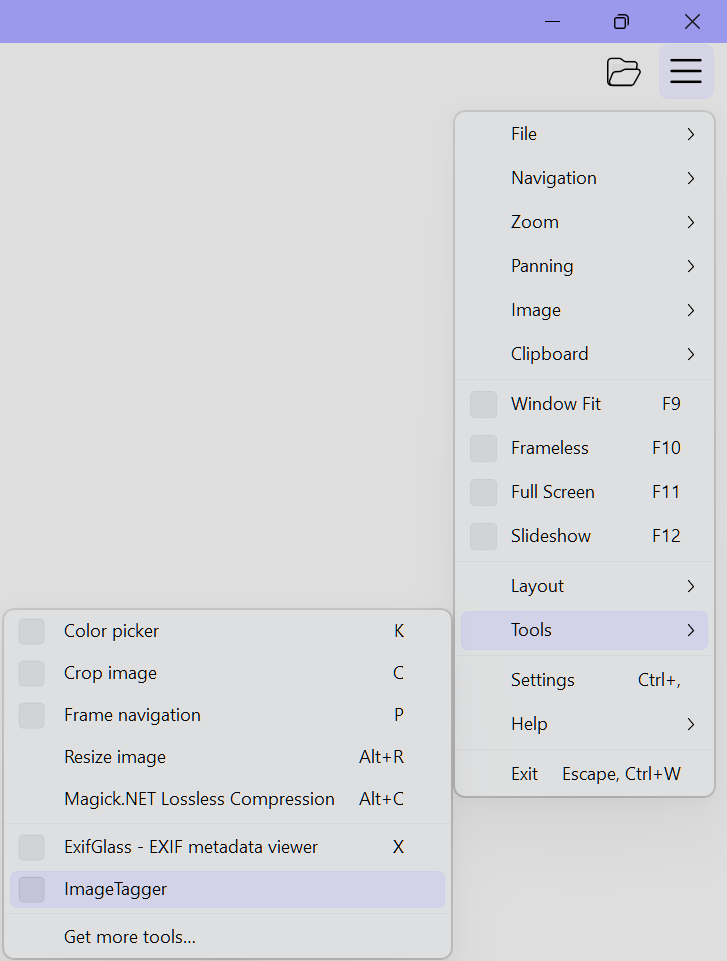
在 ImageGlass 中,通过 Settings -> Tools -> ImageTagger 启动。插件启动后会自动监听当前显示的图片路径。
4.2 标签管理
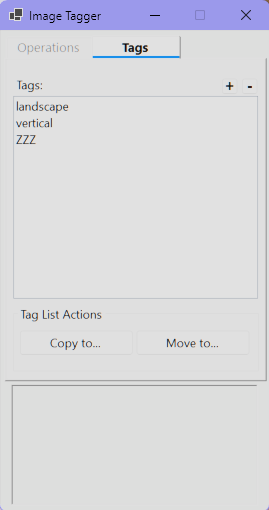
- 创建标签:在
Tags选项卡中点击+按钮,输入标签名即可。 - 删除标签:右键点击标签名称,选择
Delete菜单项。 - 快捷打标:切换到
Tagging选项卡,每个标签都会对应一个按钮,点击即可将当前图片归类。
4.3 批量操作
当打标完成后,您可以在 Tags 选项卡中对特定标签下的所有文件执行批量操作:
Copy to...:批量复制到目标文件夹。Move to...:批量移动到目标文件夹。
5. 配置说明
5.1 数据存储
所有标签和图片路径都存储在插件运行目录下的 tags.json 文件中。这是一个标准的 JSON 文件,可以手动备份或编辑(请确保格式正确)。
5.2 窗口行为
为了方便在全屏浏览图片时使用,插件默认保持 Always on Top(总在最前)。窗口高度会根据标签数量和日志条目自动调整。
6. 参与贡献
如果您在使用过程中遇到问题或有更好的建议,欢迎通过以下方式参与:
- 在
GitHub Issues提交反馈。 - 提交
Pull Request贡献代码。
7. 许可证
本项目采用 GNU General Public License v3.0 许可证。
参考文档
基于 WebDAV 协议的局域网文件传输方案与实践
1. 问题背景
在局域网 LAN 环境中进行跨设备的大文件跨节点传输或批量文件交互时,传统的标准解决方案通常是基于 SMB/CIFS 协议的 Windows 共享文件夹。然而,在异构网络及多设备协同的实际场景中,该方案常暴露出以下技术痛点:
- 访问控制与权限管理复杂:Windows 的共享权限依赖于其底层的 NTFS 权限模型与本地用户组策略 (Local Security Policy)。这导致在非域控 (AD) 环境中,跨设备认证常因凭据冲突或匿名访问策略限制,频繁触发“访问拒绝”或持续要求输入网络凭据的错误。
- 网络发现机制不稳定:基于
NetBIOS或WSD(Web Services for Devices) 的网络发现广播极易受限于局域网内`的网段隔离,虚拟网卡干扰或本地防火墙策略,导致目标主机无法在网络拓扑列表中稳定解析,通常需要回退至 IP 直连。 - 跨平台兼容性受限:尽管 macOS, iOS 及基于 Linux 的 Android 系统均已提供对 SMB 协议的支持,但在实际挂载 Windows 共享卷时,仍易出现握手延迟,大批量零碎文件读写中断或目录树加载缓慢等兼容性异常。
1.1 WebDAV 的技术定义与协议本质
WebDAV (Web-based Distributed Authoring and Versioning) 是由 IETF 在 RFC 4918 (取代了早期的 RFC 2518) 中定义的一组 HTTP 1.1 协议扩展。从技术本质上讲,它将原本仅用于“只读”内容分发的 HTTP 协议,改造成为一个具备“远程协同创作”能力的分布式文件系统。
RFC (Request for Comments) 是由 IETF (互联网工程任务组) 发布的一系列技术规范文档。它包含了互联网相关的协议、标准和政策定义。每一份 RFC 都有一个唯一的编号 (如 WebDAV 所遵循的 RFC 4918),一旦发布即成为全球开发者遵循的技术基石,确保了不同系统和软件之间的高度互操作性。
在传统的 HTTP 模型中,客户端主要通过 GET 方法获取资源;而 WebDAV 通过引入一系列全新的扩展方法,允许客户端直接在远程 Web 服务器上进行创建,修改,移动,销毁以及属性管理等操作。这种特性使得 WebDAV 成为连接 Web 技术与文件存储系统的天然桥梁,也是现代云存储服务 (如 Nextcloud, ownCloud 以及各类 NAS 厂商) 普遍支持的核心底层协议。
1.2 核心机制:语义扩展与并发控制
WebDAV 之所以能提供接近本地文件系统的操作体验,归功于其在 HTTP 之上构建的四大核心能力:
- 集合管理 (Collections):支持创建,列出和删除类似文件夹的资源集合。它通过 MKCOL 方法打破了 HTTP 原有的扁平化资源结构,实现了层级化的命名空间管理。
- 元数据处理 (Properties):利用基于 XML 的属性定义,允许用户为文件附加自定义元数据 (如作者,创建时间,摘要)。通过 PROPFIND 和 PROPPATCH 指令,客户端可以高效地查询和更新这些非结构化信息。
- 并发冲突抑制 (Locking):为了解决多人协同编辑时的“更新丢失”问题,WebDAV 按照 RFC 4918 标准实现了精细的资源锁定机制。它支持排他锁 (Exclusive Locks) 和共享锁 (Shared Locks),确保在文件写入期间资源的原子性与一致性。
- 网络适应性与防火墙穿透 (Stability & Security):由于完全构建在 TCP 80/443 端口之上,WebDAV 具备极高的网络鲁棒性。相比于依赖 TCP 445 端口 (常因勒索病毒风险被 ISP 强制封锁) 且通信机制极其“啰嗦”的 SMB,WebDAV 利用标准的 HTTP/HTTPS 协议栈,能够无缝穿透企业级防火墙和 NAT 设备。通过集成成熟的 TLS 加密标准,它不仅保障了数据在广域网传输中的私密性,还避开了 SMB 复杂的底层鉴权漏洞,实现了更高的系统安全性。
1.3 历史博弈与范式迁移:为什么主流是 Git 而非 WebDAV
尽管 WebDAV 的全称中包含 Versioning (版本控制),且早在 2002 年的 RFC 3253 中就详细定义了版本管理扩展,但现代软件工程的主流最终选择了 Git。这种分化源于两者在解决“协作冲突”与“数据一致性”上的底层范式差异:
悲观锁与乐观锁的哲学分歧:
- WebDAV 的版本控制机制核心是 悲观并发控制 (Pessimistic Concurrency Control)。它通过 LOCK 方法强制锁定资源,确保在同一时间内只有一个客户端能够进行写入。这种模式适用于不可合并的二进制大文件 (如设计稿,文档),但严重阻碍了大规模并发开发。
- Git 采用的是 乐观并发控制 (Optimistic Concurrency Control),并引入了强大的分支合并机制 (Merge/Rebase)。它允许无数开发者同时修改同一份文件,事后再通过逻辑对比解决冲突。这种范式极大地提升了软件迭代的效率。
中心化驱动与分布式驱动的架构差异:
- WebDAV 是典型的 中心化网络文件系统。所有版本操作、元数据查询都必须实时与远程服务器通信。在网络波动或大批量小文件操作时,频繁的 HTTP 握手会导致严重的性能瓶颈。
- Git 是 分布式版本控制系统 (DVCS)。它将整个代码库及其历史记录克隆到本地,绝大部分操作 (提交,查看历史,分支切换) 均为本地 I/O 操作,响应速度比基于网络的 WebDAV 快出多个数量级。
数据结构的演进:
- WebDAV 倾向于将版本视为文件的“状态快照”和“增量副本”的集合,其数据模型是为“存储”而生的。
- Git 则引入了 内容寻址存储 (Content-addressable storage) 和 有向无环图 (DAG) 结构,将版本管理提升到了逻辑链路的高度。这使得 Git 不仅能记录文件长什么样,还能完美记录代码演进的因果关系。
结论:WebDAV 在竞争中退守到了其更擅长的“分布式创作与共享”领域,成为了 NAS 存储,云盘同步和协同文档 (如早期 Office 共享) 的基石。而 Git 则凭借其极致的性能和协作效率,成为了开发者手中的标准工具。在局域网文件传输场景下,我们利用的正是 WebDAV 优秀的网络适应性与存储解耦能力,而非其原始的版本控制特性。
为构建高可用,跨平台且易于维护的文件交互通道,引入更为轻量,标准化的应用层协议栈成为必要的优化方向。
2. 架构优化:引入 WebDAV 与 RaiDrive
鉴于系统底层 SMB 协议在权限耦合与跨平台调度上的复杂性,本方案选择引入更为通用、轻量的 WebDAV 协议以替代传统共享体系。
而在 Windows 客户端侧,RaiDrive 是实现该架构闭环的关键工具。作为一款专业的虚拟文件系统映射工具,RaiDrive 能够将远端 WebDAV 资源挂载为本地逻辑驱动器,使用户可以像访问物理硬盘一样进行文件操作。
RaiDrive 在工具链中的核心价值体现在:
- 系统解耦:完全绕过了 Windows 复杂的网络共享与用户鉴权模型,通过独立账号体系建立连接,彻底解决凭据冲突问题。
- 性能优化:相较于 Windows 自带的 WebDAV 客户端 (存在单文件 50MB 限制及缓存延迟),RaiDrive 提供了更高效的数据缓冲机制和更稳定的连通性,支持大文件的高速传输。
- 无感操作:支持开机自启与静默挂载,将网络存储资源深度集成到文件资源管理器中。对于用户而言,操作 WebDAV 目录与操作 C 盘或 D 盘无异,极大地提升了生产力。
通过 Docker 容器化部署服务端与 RaiDrive 挂载客户端,我们构建了一套稳定、高性能且易于维护的局域网文件交互工具链。
3. 核心技术原原理
3.1 WebDAV 协议概述
WebDAV (Web-based Distributed Authoring and Versioning) 是一组基于 Web 体系的分布式文件管理标准。它将传统上仅作为超文本传输媒介的 HTTP 协议,扩展为具备读写能力的分布式存储层协议。客户端不仅可以获取资源,还能够对服务器端的文件和目录进行完整的 CRUD (创建,读取,更新,删除) 操作。
3.2 底层协议栈与扩展方法
WebDAV 本质上是构建于 HTTP/HTTPS 协议之上的扩展指令集。
- 标准 HTTP 方法:沿用 GET (获取数据), PUT (上传文件) 和 POST (提交处理) 等基础指令。
- WebDAV 扩展方法:在 HTTP 标准之上,新增了专用于文件系统操作的指令语义,例如:
- PROPFIND / PROPPATCH:查询或修改文件系统对象的元数据属性 (如体积,时间戳)。
- MKCOL:创建新的集合 (等同于建立目录)。
- COPY / MOVE:实现服务器端资源的高效复制与移动。
- LOCK / UNLOCK:提供并发控制机制,防止多终端协同写入时产生脏数据。
由于全面继承了 HTTP(S) 的特性,WebDAV 具备极高的网络适应性与防火墙穿透能力。
4. 技术选型对比:WebDAV vs SMB 协议
4.1 WebDAV 的核心架构优势
- 独立且轻量的鉴权机制:彻底剥离了 Windows 复杂的安全描述符与 ACL (访问控制列表) 机制。只要服务端容器正常运行,通过标准的基础认证 (Basic Authentication) 即可快速建立连接,降低了鉴权管理的复杂度。
- 全平台兼容与广域网适应性:主流操作系统与移动端环境均具备成熟的 WebDAV 客户端生态。此外,依托标准的 TCP 80/443 端口,未来若结合 VPN 或内网穿透技术 (如 Tailscale, FRP),可平滑升级至广域网远程访问架构。
- 基于直连的高网络连通率:摒弃了不稳定的局域网广播发现机制,直接采用 IP + 端口的 TCP 面向连接通信,握手成功率与链路稳定性显著提升。
4.2 传统 SMB 方案的运维劣势
- 高危端口受限:为防范 WannaCry 等利用 MS17-010 漏洞的勒索蠕虫,全球绝大多数 ISP (互联网服务提供商) 及企业级边缘路由器均在硬件层面封锁了 SMB 所依赖的 TCP 445 端口。这使得 SMB 协议基本被禁锢于纯粹的内网隔离环境中。
- 故障排查链路过长:出现连接阻断时,系统管理员需要逐一排查注册表项,SMB v1.0/v2.0 协议开关,Windows Defender 防火墙入站规则,网络配置文件类型 (公用/专用) 等底层组件,运维排障成本极高。
性能注记:在纯局域网环境下,WebDAV 因 HTTP 协议头的冗余开销,其极限 I/O 吞吐量相较于专为局域网优化的原生 SMB 可能存在微小差距。但在千兆及 2.5G 规格的现代网络介质中,WebDAV 依然能够提供足以跑满物理带宽的数据传输率,对业务的实际性能影响可忽略不计。
5. 部署实践与标准操作程序 (SOP)
本次部署实践基于 Windows 宿主机与 Docker 环境,采用具有高稳定性的轻量级官方镜像 (bytemark/webdav)。
5.1 服务端部署 (基于 Docker)
通过容器化方式拉起 WebDAV 进程,并映射本地物理卷。
⚠️ 关键配置说明:数据卷映射参数必须精准指向容器内的 WebDAV 标准数据存放路径 /var/lib/dav/data。若错误地映射至其父级目录,将导致客户端连接成功但无法获取文件树的异常状态。
执行以下初始化命令:
docker run -d \
--name webdav-server \
-e AUTH_TYPE=Basic \
-e USERNAME=admin \
-e PASSWORD=YourSecurePassword \
-p 8083:80 \
-v D:\share:/var/lib/dav/data \
bytemark/webdav
环境依赖:需在 Windows 高级安全防火墙中添加对应的入站规则,放行 TCP 8083 端口。
5.2 客户端资源挂载 (以 RaiDrive 为例)
为规避 Windows 系统自带 WebDAV 客户端的先天限制 (如默认拒绝纯 HTTP 环境的基础认证,以及硬编码的 50MB 单文件下载限制阈值),本方案指定使用 RaiDrive 作为客户端挂载介质。
- 点击
Add按钮,新建存储配置。 - 存储协议类型选择
NAS分页下的WebDAV选项。 - 网络协议降级:取消勾选
HTTPS选项,强制采用纯 HTTP 传输 (仅限内网可信环境)。 - 节点寻址:在
Address栏填写目标服务端的内网 IP 地址 (例如 192.168.31.77),服务端口指定为 8083。 - 根目录映射:将
Path严格配置为根路径 /。 - 提交已设定的认证凭据 (admin 及对应密码),建立连接后,系统将自动映射逻辑驱动器 (如 Z: 盘),实现文件资源的高效管理。
6. 结语
面向多设备协同与异构操作系统的局域网文件交互场景,采用 Docker 容器化部署的 WebDAV 服务提供了一套标准,稳定且低耦合的技术方案。通过配合 RaiDrive 等专业客户端,该架构不仅有效规避了底层系统权限配置的复杂性,更通过高度集成的工具链提升了跨平台协作效率,为未来业务向外网拓展奠定了良好的网络协议基础。
参考文档
- RFC 4918 - HTTP Extensions for Web Distributed Authoring and Versioning (WebDAV)
- WebDAV - Wikipedia
- WebDAV Resources
- WebDAV API Documentation - Nextcloud Developer Manual
- Accessing ownCloud Files Using WebDAV - ownCloud Documentation
- bytemark/webdav - Docker Hub
- BytemarkHosting/docker-webdav - GitHub
- RaiDrive - Mount cloud storage as a local drive
在 Linux 中使用 Ventoy 制作 Windows 启动盘
Ventoy 是一个开源的多系统启动 U 盘解决方案,支持直接从 ISO/WIM/VHD(x)/EFI 文件启动,无需反复格式化 U 盘。
1. 准备工作
1.1 获取 Windows ISO 镜像
三选一,建议使用非官方源(Microsoft 官网可能会有神秘报错):
- OS.click(推荐):https://os.click/en
- UUP dump:https://uupdump.net/
- Microsoft 官网:https://www.microsoft.com/software-download/windows11
下载完成后校验文件:
sha256sum windows11.iso
2. 安装 Ventoy
2.1 下载 Ventoy
访问 Ventoy 官网 下载 Linux 版本安装包,例如 ventoy-1.0.00-linux.tar.gz。
解压安装包:
tar -xzf ventoy-1.0.00-linux.tar.gz
cd ventoy-1.0.00
2.2 使用 WebUI 制作 Windows 启动盘
Ventoy 提供了 WebUI 图形化界面,推荐使用此方式安装,GUI 版本可能导致未响应。
- 启动 WebUI 服务器:
sudo ./VentoyWeb.sh
启动后会显示以下提示信息:
===============================================================
Ventoy Server 1.1.07 is running ...
Please open your browser and visit http://127.0.0.1:24680
===============================================================
################## Press Ctrl + C to exit #####################
- 打开浏览器访问:
在浏览器中打开 http://127.0.0.1:24680。
- 在 WebUI 中安装:
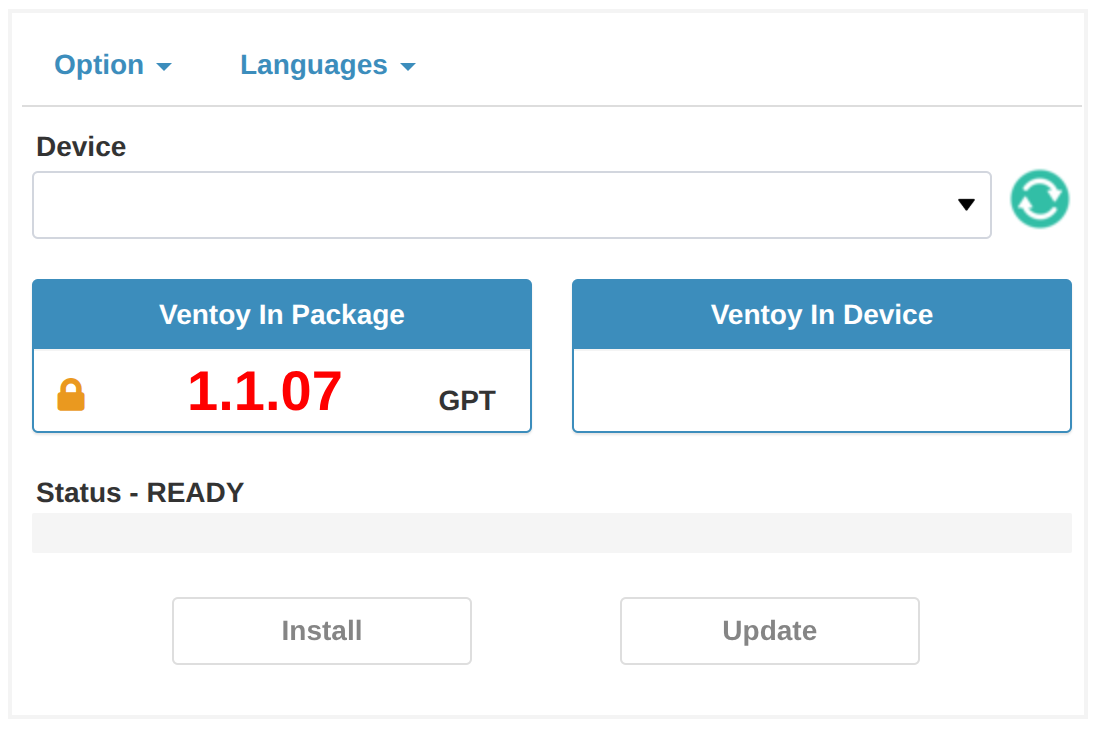
WebUI 界面如下图所示:
界面说明:
- 设备选择:
Device下拉框选择目标 U 盘设备,右侧绿色刷新按钮可重新扫描设备 - 版本信息:
- Ventoy In Package:显示安装包中的 Ventoy 版本(如 1.1.07)和分区格式(MBR/GPT)
- Ventoy In Device:显示设备中已安装的 Ventoy 版本,如果为空则表示未安装
- Option 菜单:
- Secure Boot Support:启用安全启动支持,建议勾选以兼容支持 UEFI Secure Boot 的计算机,在一些品牌笔记本电脑安装中,如果不启用安全会导致无法安装系统
- Partition Style:选择分区格式,可选择
MBR(Legacy BIOS)或GPT(UEFI) - Partition Configuration:分区配置选项,可设置在U盘内的保留空间
- Clear Ventoy:清除设备中的 Ventoy
- Show All Devices:显示所有设备
- 状态显示:
Status - READY表示准备就绪 - 操作按钮:
Install:安装 Ventoy 到 U 盘Update:升级设备中的 Ventoy 版本
在 WebUI 中执行以下操作:
- 选择目标 U 盘设备
- 选择分区格式(MBR 或 GPT)
- 选择文件系统类型(exFAT, NTFS, FAT32 等)
- 点击
安装按钮
注意: 安装会格式化 U 盘,清除所有数据。普通 U 盘建议使用 exFAT 文件系统,大容量移动硬盘或 SSD 建议使用 NTFS 文件系统。
3. 拷贝镜像文件
安装完成后,U 盘会被分成两个分区:
- 第 1 个分区(镜像分区):容量较大,用于存放 ISO 文件
- 第 2 个分区(VTOYEFI 分区):32MB,存放 Ventoy 启动文件
将下载的 Windows ISO 镜像文件直接拷贝到第 1 个分区(大一点的分区)中即可。可以将文件放在任意目录及子目录下,Ventoy 会自动遍历所有目录,按字母顺序显示在启动菜单中。
注意: 安装完成后,镜像分区也可以手动重新格式化为其他支持的文件系统(exFAT/FAT32/NTFS/UDF/XFS/Ext2/3/4),不影响 Ventoy 功能。
4. 启动安装
4.1 设置启动顺序
- 重启计算机,进入 BIOS/UEFI 设置
- 将 U 盘设置为第一启动项
- 保存并退出
4.2 选择镜像启动
从 U 盘启动后,Ventoy 会显示镜像文件列表,选择要安装的 Windows ISO 文件即可开始安装。
4.3 目标分区格式要求
重要提示: 如果目标安装位置(通常是系统盘)使用 GPT 分区表且格式为 NTFS,安装过程中可能会出现错误。建议在安装 Windows 前,将目标安装位置格式化为 GPT 格式,以避免安装失败。
5. 注意事项
- 安装 Ventoy 会格式化 U 盘,清除所有数据,请提前备份重要文件
- U 盘容量需至少 8GB(推荐 16GB 或更大)
- 可以将 U 盘当作普通存储设备使用,存放普通文件不影响 Ventoy 功能
- 支持同时存放多个 ISO 文件,启动时可以选择
- MBR/GPT 分区格式选项只在安装时有效,升级不会改变现有分区格式
参考文档
使用 Whisper Tiny 模型实现快速语音转文字:Python 部署与实践指南
1. 环境准备
1.1 系统要求
- 操作系统:Ubuntu / Debian / WSL / macOS / Windows
- Python:3.10 或更高版本
- 系统依赖:
ffmpeg(Whisper 处理音频文件必需)
1.2 安装系统依赖
Ubuntu/Debian:
sudo apt-get update
sudo apt-get install -y ffmpeg
macOS:
brew install ffmpeg
Windows: 从 ffmpeg.org 下载并安装
1.3 安装 Python 依赖
pip install openai-whisper
或者使用项目 requirements.txt:
pip install -r requirements.txt
2. Whisper 模型选择
Whisper 提供多种模型,可根据需求选择:
| 模型 | 参数量 | 速度 | 准确度 | 推荐场景 |
|---|---|---|---|---|
tiny | 3900万 | 最快 | 较低 | 实时交互、低延迟需求 |
base | 7400万 | 较快 | 中等 | 平衡速度和准确度 |
small | 2.44亿 | 中等 | 较好 | 一般应用 |
medium | 7.69亿 | 较慢 | 较高 | 高准确度需求 |
large | 15.5亿 | 最慢 | 最高 | 专业转录 |
本项目使用 tiny 模型,适合实时语音交互场景。
3. 核心功能实现
3.1 模型管理(单例模式)
import whisper
import warnings
_whisper_model = None
def get_whisper_model():
"""获取或加载Whisper模型(单例模式)"""
global _whisper_model
if _whisper_model is None:
with warnings.catch_warnings():
warnings.filterwarnings("ignore", message="FP16 is not supported on CPU")
_whisper_model = whisper.load_model("tiny", device="cpu")
return _whisper_model
特点:
- 延迟加载:首次使用时才加载模型
- 单例模式:全局只加载一次,节省内存
- 自动处理 CPU/GPU:根据设备自动选择
注意:首次运行时会自动下载模型文件(tiny 模型约 75MB),下载完成后会缓存到本地,后续运行会直接使用缓存,无需重新下载。
3.2 音频文件处理
async def process_audio_file(audio_content: bytes, filename: str):
"""处理音频文件并转写"""
# 1. 验证文件格式
validate_audio_file(filename, audio_content)
# 2. 保存到临时文件
temp_path = create_temp_file(audio_content, filename)
# 3. 转写音频
result = transcribe_audio_file(temp_path, filename)
# 4. 清理临时文件
cleanup_temp_file(temp_path)
return result
支持的音频格式:
.mp3,.wav,.flac,.m4a,.ogg,.webm,.mpeg,.mp4
注意:Whisper 会自动通过 ffmpeg 处理各种音频格式,无需手动转换。确保系统已安装 ffmpeg。
3.3 API 接口
可以使用 FastAPI 等 Web 框架封装 Whisper 功能,提供 HTTP API 接口。典型的接口设计包括:
语音转文字接口示例:
from fastapi import FastAPI, File, UploadFile
import whisper
app = FastAPI()
model = whisper.load_model("tiny")
@app.post("/transcribe")
async def transcribe_audio(audio: UploadFile = File(...)):
"""语音转文字接口"""
# 保存上传的音频文件
temp_path = save_temp_file(audio)
# 转写音频
result = model.transcribe(temp_path, language="zh")
# 清理临时文件
cleanup_temp_file(temp_path)
return {
"text": result["text"],
"language": result["language"]
}
4. 快速开始
4.1 最小示例
import whisper
# 加载模型(首次会自动下载)
model = whisper.load_model("tiny")
# 转写音频文件
result = model.transcribe("audio.wav", language="zh")
print(result["text"])
4.2 使用 FastAPI 接口
启动服务:
uvicorn main:app --reload
测试接口:
# 转写接口示例
curl -X POST \
-F "audio=@test.wav" \
http://localhost:8000/transcribe
4.3 Python 代码调用
import whisper
# 加载模型
model = whisper.load_model("tiny")
# 转写音频文件
result = model.transcribe("audio.wav", language="zh")
# 输出结果
print(f"转写结果: {result['text']}")
print(f"检测语言: {result['language']}")
print(f"处理时间: {result.get('processing_time', 'N/A')}")
5. 配置说明
5.1 修改模型类型
修改模型名称:
# 使用 tiny 模型(推荐,速度快)
_whisper_model = whisper.load_model("tiny", device="cpu")
# 或使用其他模型
_whisper_model = whisper.load_model("base", device="cpu")
_whisper_model = whisper.load_model("small", device="cpu")
注意:如需提高转写准确度,可以:
- 使用更大的模型(small/medium/large),但速度会变慢
- 确保音频质量良好,减少背景噪音
- 指定正确的语言参数,避免自动检测带来的延迟
5.2 设备选择
# CPU 推理(默认)
model = whisper.load_model("tiny", device="cpu")
# GPU 推理(需要 CUDA)
model = whisper.load_model("tiny", device="cuda")
注意:Tiny 模型在 CPU 上运行速度已经很快,适合大多数场景。如需进一步提升速度,可以考虑:
- 使用 GPU 推理(需要安装 CUDA 版本的 PyTorch)
- 使用更小的模型(但准确度会降低)
5.3 语言指定
# 自动检测语言(默认)
result = model.transcribe("audio.wav")
# 指定语言(更快)
result = model.transcribe("audio.wav", language="zh") # 中文
result = model.transcribe("audio.wav", language="en") # 英文
参考文档
使用fuck-u-code优化代码质量
fuck-u-code 是一款专门揭露屎山代码的质量分析工具,能够评估代码的"屎山等级"并输出美观的报告,可以输出md格式报告,供大模型分析使用。
项目介绍
项目地址: https://github.com/Done-0/fuck-u-code
项目描述: Legacy-Mess Detector – assess the “legacy-mess level” of your code and output a beautiful report | 屎山代码检测器,评估代码的"屎山等级"并输出美观的报告
核心特性
- 多语言支持: Go、JS/TS、Python、Java、C/C++
- 屎山指数: 0~100 分,越高越烂
- 七维度检测: 复杂度 / 函数长度 / 注释率 / 错误处理 / 命名 / 重复度 / 结构
- 彩色终端报告: 批评也能笑着听
- Markdown 输出: 方便 AI 分析与文档集成
- 灵活配置: 摘要 / 详细模式,多语言报告
- 全程本地运行: 不上传代码,安全无忧
安装方法
方法一:Go 安装(推荐)
go install github.com/Done-0/fuck-u-code/cmd/fuck-u-code@latest
方法二:源码构建
git clone https://github.com/Done-0/fuck-u-code.git
cd fuck-u-code && go build -o fuck-u-code ./cmd/fuck-u-code
方法三:Docker 构建
docker build -t fuck-u-code .
基本使用方法
分析本地项目
# 基本分析 - 本地项目
fuck-u-code analyze /path/to/project
# 或
fuck-u-code /path/to/project
# 默认分析当前目录
fuck-u-code analyze
分析 Git 仓库
# 分析 Git 仓库(自动克隆)
fuck-u-code analyze https://github.com/user/repo.git
# 或
fuck-u-code https://github.com/user/repo
Docker 运行
docker run --rm -v "/path/to/project:/build" fuck-u-code analyze
常用选项
| 选项 | 简写 | 描述 |
|---|---|---|
--verbose | -v | 显示详细报告 |
--top N | -t | 最烂的前 N 个文件 |
--issues N | -i | 每文件显示 N 个问题 |
--summary | -s | 只看总结,不看过程 |
--markdown | -m | 输出 Markdown 格式报告 |
--lang | -l | 报告语言 (zh-CN/en-US/ru-RU) |
--exclude | -e | 排除指定目录或文件 |
--skipindex | -x | 跳过 index.js/ts 文件 |
使用示例
fuck-u-code analyze --verbose
fuck-u-code analyze --top 3
fuck-u-code analyze --lang en-US
fuck-u-code analyze --summary
fuck-u-code analyze --exclude "**/test/**"
fuck-u-code analyze --markdown > report.md
代码质量分析脚本
基于 fuck-u-code 工具,我编写了一个简单的代码质量分析脚本,用于自动生成 Markdown 格式的代码质量报告。
脚本内容
创建 analyze_code_quality.sh 文件:
#!/bin/bash
# 代码质量分析脚本
fuck-u-code analyze --markdown --lang zh-CN --skipindex --exclude "**/tests/**" > code_quality_report.md
echo "代码质量分析完成,报告已生成:code_quality_report.md"
使用方法
# 1. 创建脚本文件
nano analyze_code_quality.sh
# 将上述脚本内容复制到文件中
# 2. 赋予执行权限
chmod +x analyze_code_quality.sh
# 3. 运行脚本
./analyze_code_quality.sh
脚本参数说明
--markdown: 输出 Markdown 格式报告--lang zh-CN: 使用中文语言--skipindex: 跳过 index.js/ts 文件--exclude "**/tests/**": 排除测试目录
输出文件
code_quality_report.md- 代码质量分析报告
Markdown 输出
适合 AI 分析、文档集成、CI/CD、团队协作
fuck-u-code analyze --markdown
fuck-u-code analyze --markdown > report.md
fuck-u-code analyze --markdown --top 10 --lang en-US > report.md
默认排除路径
- 前端:
node_modules,dist,build,*.min.js等 - 后端:
vendor,bin,target,logs,migrations等
疑难解答
常见问题
command not found错误
# 把 Go bin 路径加到 PATH
export PATH="$PATH:$(go env GOPATH)/bin"
# 并写入 .bash_profile / .zshrc 等
- 权限错误
chmod +x analyze_code_quality.sh
chmod +x quick_analyze.sh
- fuck-u-code 未安装
go install github.com/Done-0/fuck-u-code/cmd/fuck-u-code@latest
- 不在项目根目录
- 确保在包含
requirements.txt和app/目录的根目录运行
- 分析失败
- 检查
logs/analysis_error.log文件 - 确保项目代码没有语法错误
报告解读
评分系统
- 分数范围: 0~100 分
- 分数含义: 越高越烂,欢迎"高分大佬"上榜
- 七维度检测:
- 复杂度分析
- 函数长度检查
- 注释率统计
- 错误处理评估
- 命名规范检查
- 重复度检测
- 代码结构分析
生成的 Markdown 报告包含
- 📊 整体质量评分
- 📈 各项指标详情
- 🔍 问题文件列表
- 💡 改进建议
改进重点
根据报告中的优先级进行代码改进,重点关注:
- 高复杂度函数
- 重复代码
- 缺少注释
- 错误处理
Markdown 转 PDF 加水印工具
一个功能强大的Markdown转PDF工具,支持GitHub风格的Markdown语法、代码文档、Mermaid图表等,并自动添加水印。专为技术文档和代码项目设计,支持中文字体渲染和批量处理。
功能特性
- Markdown → PDF(GitHub样式):表格、代码块、链接、图片;多语言代码高亮
- Mermaid 支持:流程图、时序图、甘特图自动渲染
- 水印能力:文本/图片水印、透明度/角度/密度可调,亦可输出无水印
- 中文字体:自动识别常见中文字体,渲染稳定
- 批量处理:
input/全目录一键处理,结果输出至output/ - 交互/默认双模式:交互式最少参数配置;快速模式开箱即用
- 多语言界面:中英自动/手动切换
适用:README/设计与架构(Mermaid)/API与代码文档、技术博客归档、项目报告与教学讲义;支持批量加水印或生成纯净PDF,便于团队分发协作。
快速开始
运行项目
git clone https://github.com/pinyinjj/Markdown-to-PDF-Tool.git
cd md-pdf-watermark
python main.py
程序会引导您选择操作模式:
1. 处理PDF文件(添加水印)
- 为现有PDF文件添加水印
- 支持批量处理多个PDF文件
2. 转换Markdown到PDF(添加水印)
- 将Markdown文件转换为PDF并添加水印
- 支持Mermaid图表和代码高亮
- 自动检测中文字体
3. 仅生成图片水印
- 只生成水印图片,不处理任何文件
- 适合批量生成水印素材
- 支持文本和图片两种水印类型
4. 转换Markdown到PDF(无水印)
- 将Markdown文件转换为PDF,不添加水印
- 支持Mermaid图表和代码高亮
- 适合需要纯净PDF的场景
详细安装说明
Windows 安装
安装Python
- 从 python.org 下载Python 3.8+
- 安装时勾选"Add Python to PATH"
安装依赖
pip install -r requirements.txt playwright install系统依赖(如果需要)
playwright install-deps
Linux 安装
安装Python
# Ubuntu/Debian sudo apt update sudo apt install python3 python3-pip python3-venv # CentOS/RHEL sudo yum install python3 python3-pip安装依赖
pip install -r requirements.txt playwright install系统依赖
sudo playwright install-deps
国际化支持
语言设置
程序支持英文和中文两种界面语言:
自动语言检测
程序会自动检测系统语言环境:
- 检测系统
locale设置 - 检查环境变量
LANG - 默认使用英文作为后备语言
手动语言设置
# 使用英文界面
python main.py --lang en --interactive
# 使用中文界面
python main.py --lang zh --interactive
# 自动检测(默认)
python main.py --interactive
语言切换
- 在交互式模式中,语言设置会影响所有界面文本
- 包括菜单选项、提示信息、错误消息等
- 不影响处理的文件内容
配置说明
水印配置
程序使用WatermarkConfig类管理所有配置:
class WatermarkConfig:
# 文本水印设置
GENERATE_IMAGE_FROM_TEXT = True # 是否从文本生成图片水印
TEXT_WATERMARK_FILE = "watermarks/text_watermark.png" # 文本水印图片文件名
FONT_SIZE = 36 # 字体大小
TEXT_COLOR = (68, 68, 68, 220) # 文本颜色RGBA
PADDING = 20 # 内边距
# PDF水印参数
WATERMARK_TYPE = "grid" # 水印类型:grid/insert
OPACITY = 0.2 # 透明度
ANGLE = 45 # 旋转角度
IMAGE_SCALE = 1.0 # 图片缩放
HORIZONTAL_BOXES = 3 # 水平网格数
VERTICAL_BOXES = 6 # 垂直网格数
字体配置
程序会自动检测系统中文字体,支持:
- Windows: 微软雅黑、黑体、宋体、楷体、仿宋等
- Linux: Noto Sans CJK等
如需指定字体,可设置环境变量:
export WATERMARK_FONT="/path/to/your/font.ttf"
使用方法
基本使用
- 准备文件:将PDF或Markdown文件放入
input/目录 - 运行程序:执行
python main.py - 查看结果:处理后的文件在
output/目录
调整水印样式
修改WatermarkConfig中的相关参数:
# 调整透明度
OPACITY = 0.3
# 调整角度
ANGLE = 30
# 调整网格密度
HORIZONTAL_BOXES = 4
VERTICAL_BOXES = 8
故障排除
常见问题
- Playwright浏览器未安装
playwright install
- 中文字体未找到
- 确保系统已安装中文字体
- 或设置
WATERMARK_FONT环境变量
- watermark命令未找到
- 确保已安装
pdf-watermark包 - 检查虚拟环境是否正确激活
- 确保已安装
- 权限问题
# Linux
sudo playwright install-deps
调试模式
程序会输出详细的处理信息,包括:
- 文件处理状态
- 水印生成过程
- 错误信息
依赖包说明
| 包名 | 版本 | 用途 |
|---|---|---|
| Pillow | >=9.0.0 | 图像处理,生成文本水印图片 |
| markdown | >=3.4.0 | Markdown文件处理 |
| playwright | >=1.30.0 | 浏览器自动化,PDF渲染 |
| pdf-watermark | >=0.1.0 | PDF水印添加 |
许可证
本项目采用 GPL-3.0-or-later 许可证发布。
注意:首次运行可能需要下载Playwright浏览器,请确保网络连接正常。